
What is an enterprise
data warehouse?
An enterprise data warehouse (EDW) is a data management system optimized for business intelligence (BI) and analytics. It is a central repository for storing and managing large amounts of structured and semi-structured data from multiple sources, often spanning an entire organization.
Data is typically processed before it enters the warehouse, where it can be easily queried, mined, and visualized to help drive more informed business decisions.

Why use an enterprise
data warehouse?
Data warehouses have been a staple of enterprise data management for over 30 years. Despite the growing popularity of data lakes and data lakehouses, enterprise data warehouses remain a core component of business intelligence strategies for countless organizations worldwide.
Enterprise data warehouses offer a variety of benefits over alternative data management architectures:
- Provide a single source of truth for consistent data analysis across the organization
- Optimized for rapid data querying, accelerating BI activities
- Support analyzing vast volumes of data
OLAP, OLTP, and HTAP data processing
OLAP vs OLTP
There are two main types of data processing: online analytical processing (OLAP) and online transactional processing (OLTP).
Data warehouses are typically optimised for OLAP workloads, aiming at enabling rapid analysis of large, multi-dimensional datasets. Some data warehouses might not be fit for OLTP workloads involving multiple concurrent transactions.
HTAP
Hybrid transaction/analytical processing (HTAP) is a third kind of data processing that combines both analytical and transactional processing. Certain database solutions, such as PostgreSQL, can be used as HTAP solutions, potentially reducing infrastructure complexity and maintenance effort.
Data warehouse architecture
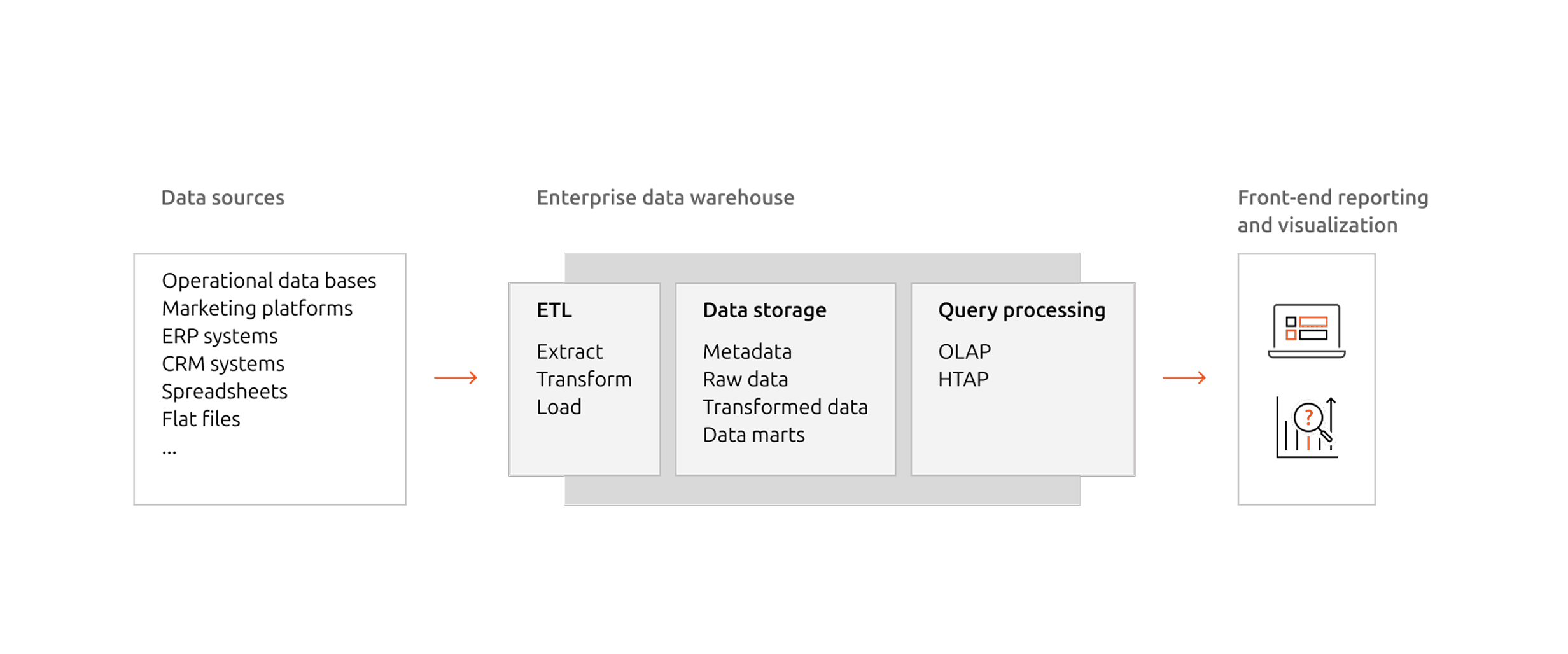
A data warehouse deployment architecture typically includes the following components:
- Data sources: In this layer, structured and semi-structured data is ingested from various sources, such as operational databases, spreadsheets, or third-party applications.
- ETL: Before data can be stored or used in analysis, it needs to be cleaned and formatted. This process is called extract, transform, load (ETL).
- Data storage: Following ETL, data is stored in the storage layer. The data might be organized in a deliberate structure to optimize query speed for specific use query patterns.
- Query processing: This layer enables fast, multi-dimensional analysis of the data stored in the data warehouse.
- Front-end reporting and visualization: This layer enables users to interact with the data through front-end user interfaces, reporting tools, and dashboards.
To see how these elements relate to one another, explore the diagram:
Enterprise data warehouse use cases
Enterprise data warehouses have countless applications across industries, wherever organizations need to turn large volumes of raw data into valuable insights.
Use cases include:
- Trend analysis and forecasting
- Customer behavior analysis
- Compliance and auditing
- Business reporting
- Inventory management
- Fraud detection
- Geospatial analysis
Canonical's solution for
enterprise data warehouses
Canonical offers an enterprise solution for data warehouses based on PostgreSQL – the proven, open source database management system with a 30 year track record.
Charmed PostgreSQL is our solution for simplifying the deployment, maintenance and upgrades of your PostgreSQL databases. With it, you can meet the needs of both your transactional and analytical use cases, without duplicating your data or enduring stale views.
We support a large number of PostgreSQL extensions including timescale, postgis, pgrouting, and pgvector to help you perform analytical queries on all your data types without leaving the comfort of an OLTP capable database management system. We also offer blueprints to separate your analytical and transactional traffic while using the same highly available deployment.
Charmed PostgreSQL brings you up to 10 years of security maintenance, enterprise support from Canonical, and advanced deployment and operations automation to help you get the most out of your PostgreSQL-based data warehouse.
Questions? Get answers

Do you have a data warehouse project in mind and want to get advice on implementing PostgreSQL? Contact us now to discuss your needs.